QuickStart Approach
This QuickStart serves as an introduction to using Snowflake Snowpark (Snowpark) to create user defined functions (UDF) and leverage them directly in Sigma to enable advanced functionality with ease.
There are many areas of discussion possible as Snowpark can be leveraged for data quality, data modeling, machine learning (ML), data science, analytics and more. With that in mind, we will narrow the scope for this QuickStart to high level education on Snowpark with a focus on UDF's and using them in Sigma.
Persona for this QuickStart
We will demonstrate, (at a high-level) how we can start to use Snowpark, as a developer (using Python) might. Given the depth of Snowpark, we will start with what amounts to a "Hello World" sort of use case.
This will give us the foundational software configurations and a base understanding of the workflow involved. In subsequent QuickStarts, we will increase the complexity by diving into specific uses cases found in real world applications, leveraging Sigma.
For more information on Sigma's product release strategy, see Sigma product releases.
### Target Audience Anyone interested in learning about Snowpark and how to leverage UDFs in Sigma.
Developers who are interested in creating Snowpark UDFs in Python (and other supported languages) and leverage them within Sigma to provide advanced functionality to Sigma users.
Prerequisites
- A computer with a current browser. It does not matter which browser you want to use.
- Access to your Sigma environment. A Sigma trial environment is acceptable and preferred.
- A Snowflake account with the proper administrative and security admin access.
- A development environment of choice. We will demonstrate with Microsoft VSCode and related extensions
- Miniconda for required Python packages
What You'll Learn from here
We will learn how to setup a local development environment, configure it for Python, connect to Snowflake, create and test a Snowpark UDF and call it from Sigma.
What You'll Build
We will build a Snowpark UDF that expects two input values and calculates the greatest common denominator and returns a value for a new table column in Sigma.

What is Snowpark?
Snowpark is a feature of the Snowflake Data Cloud platform that allows developers to write custom code using popular programming languages like Java, Scala, and Python, and execute it directly within Snowflake. It provides a powerful and flexible way to process data within Snowflake without having to move data in and out of the platform.
With Snowpark, developers can write custom data processing code that can be executed on data stored in Snowflake.
Snowpark uses a custom SQL pushdown mechanism to optimize code execution and minimize data movement.
This means that developers can write complex data processing logic using familiar programming languages, while leveraging the power and scalability of Snowflake's cloud-based data warehouse.
Some of the key benefits of using Snowpark include:
<ol type="n">
<li><strong>Simplified data processing:</strong> Snowpark provides a powerful and flexible way to process data within Snowflake without having to move data in and out of the platform, which simplifies the data processing pipeline and reduces complexity.
<li><strong>Efficient data processing:</strong> Snowpark uses a custom SQL pushdown mechanism to optimize code execution and minimize data movement, which makes data processing more efficient and reduces the overall processing time.</li>
<li><strong>Language flexibility:</strong> Snowpark supports popular programming languages like Java, Scala, and Python, which allows developers to write code using the language they are most comfortable with.</li>
<li><strong>Third party development environments:</strong> Snowpark supports developers using their preferred tools to connect to Snowflake and publish code to Snowpark.</li>
</ol>
Snowpark Worksheets
Snowpark Worksheets provide interactive notebooks that allow developers to write, test, and execute custom code directly within Snowflake. These worksheets provide a powerful and flexible way to develop and test data processing logic using the Snowflake Data Cloud platform.
For the this QuickStart we will focus on Python, but the other supported languages provide similar methods in general.
Snowpark worksheets for Python provide a familiar environment for Python developers to work with. Developers can use popular Python libraries like pandas, NumPy, and scikit-learn to read, process, and analyze data stored in Snowflake. The worksheets also support the use of Snowpark APIs and libraries for working with Snowflake-specific features like Snowflake metadata, security, and data sharing.
Some of the key features of Snowpark worksheets for Python include:
<ol type="n">
<li><strong>Interactive development environment:</strong> Snowpark worksheets provide a rich and interactive environment for developing Python-based data processing logic. Developers can write and execute code within the worksheet, and see the results immediately.</li>
<li><strong>Familiar Python environment:</strong> Snowpark worksheets support the use of popular Python libraries like pandas, NumPy, and scikit-learn, which allows developers to work with familiar tools and frameworks.
<li><strong>Seamless integration with Snowflake:</strong> Snowpark worksheets integrate seamlessly with other Snowflake features like data sharing and data marketplace, which makes it easy to develop and deploy data solutions using Snowflake.</li>
<li><strong>Secure and scalable:</strong> Snowpark worksheets provide a secure and scalable environment for developing and testing Python-based data processing logic. Snowflake's cloud-based data warehouse provides the scalability and reliability required for processing large amounts of data.</li>
</ol>
Overall, Snowflake Snowpark worksheets for Python provide a powerful and flexible environment for developing and testing custom Python-based data processing logic directly within Snowflake. This allows developers to take full advantage of the Snowflake Data Cloud platform and its capabilities for data processing and analysis.
The impact of Snowpark
As of January 31, 2023 Snowflake has more than 7,820 customers, including 573 of the Forbes Global 20002, and continues to grow rapidly.
Given the size of Snowflake's installed base, the implications of Snowpark on the Machine Learning (ML) and Data Science markets are significant and could potentially have several impacts, including:
<ol type="n">
<li><strong>Improved Efficiency:</strong> With Snowpark, data scientists and developers can write and run code directly on the Snowflake platform, which can lead to improved efficiency and faster development cycles. This could potentially lead to the creation of more accurate and reliable ML models.
<li><strong>Increased Collaboration:</strong> Snowpark enables data scientists and developers to collaborate more easily on projects by allowing them to work on the same platform and share code and data. This could potentially lead to more efficient and effective teamwork and could also foster innovation.
<li><strong>Enhanced Data Management:</strong> Snowpark could potentially improve data management by allowing data scientists to work directly with the data on the Snowflake platform. This could lead to better data governance, security, and quality.</li>
<li><strong>Competition:</strong> The introduction of Snowpark could potentially increase competition in the ML and data science markets as Snowflake is a major player in the cloud data platform space. Other vendors may need to develop similar features to remain competitive.</li>
</ol>
Considering all of this, Snowpark is something that data professionals need to pay attention to.
We will start by setting up our local Python environment based on Miniconda, which is a "thin" version of Conda.
Conda is an open-source, cross-platform, language-agnostic package manager and environment management system. It was originally developed to solve difficult package management challenges faced by Python data scientists, and today is a popular package manager for Python and R.
Miniconda is the much smaller (about 200 MB vs. 4+ gig) installer version of Conda and will save us time and disk-space compared with installing the full Conda (Anaconda) application.
It includes only Conda, Python, the packages they depend on, and a small number of other useful packages, including pip, zlib and a few others. Packages that are not included, have to be called at runtime or installed individually.
Use the following link to download the Miniconda. Download the version that includes Python 3.8 or above based on your operating system and its configuration (32 bit or 64 bit).
After downloading the operation system appropriate version from Miniconda, go ahead and run the installation, accepting the license and all the defaults.
Now that Miniconda is installed (along with our selected version of Python; v3.8), we can move to the next step.
Install VSCode from Microsoft's download site.
Run the installation with all defaults.
Once the software is installed, we need to configure it for our use case.
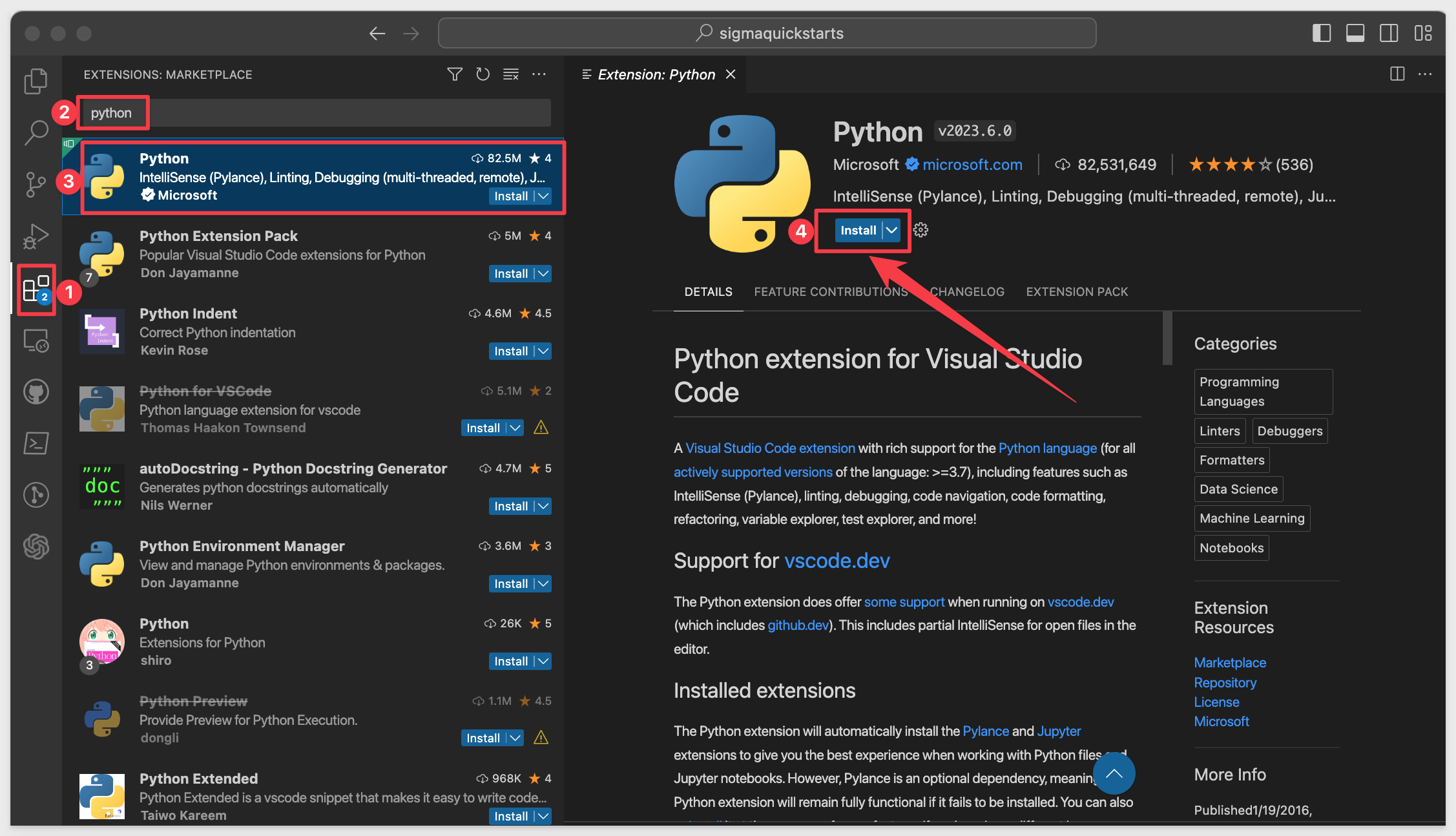
Open VSCode and click the sidebar icon for Extentions.
Search for Python and select the extension from the list as shown. Click Install:
We now have a development environment ready but we need to do a few more steps.
Since we installed Miniconda, every available Conda package is not present in our system. While this saves install time and saves disk-space, we will have to be aware that each VScode project will need to have required package dependencies installed at runtime.
We could solve this by installing packages globally but we prefer to avoid that and maintain tight control of our development environment.
To properly support this control, we will make use of Python environments to create project/package isolation.
For our first project, we will create a Python environment called snowpark.
In our local computer, navigate to where Miniconda is installed. The default is based on your computer username.
Right-click and open a terminal session:
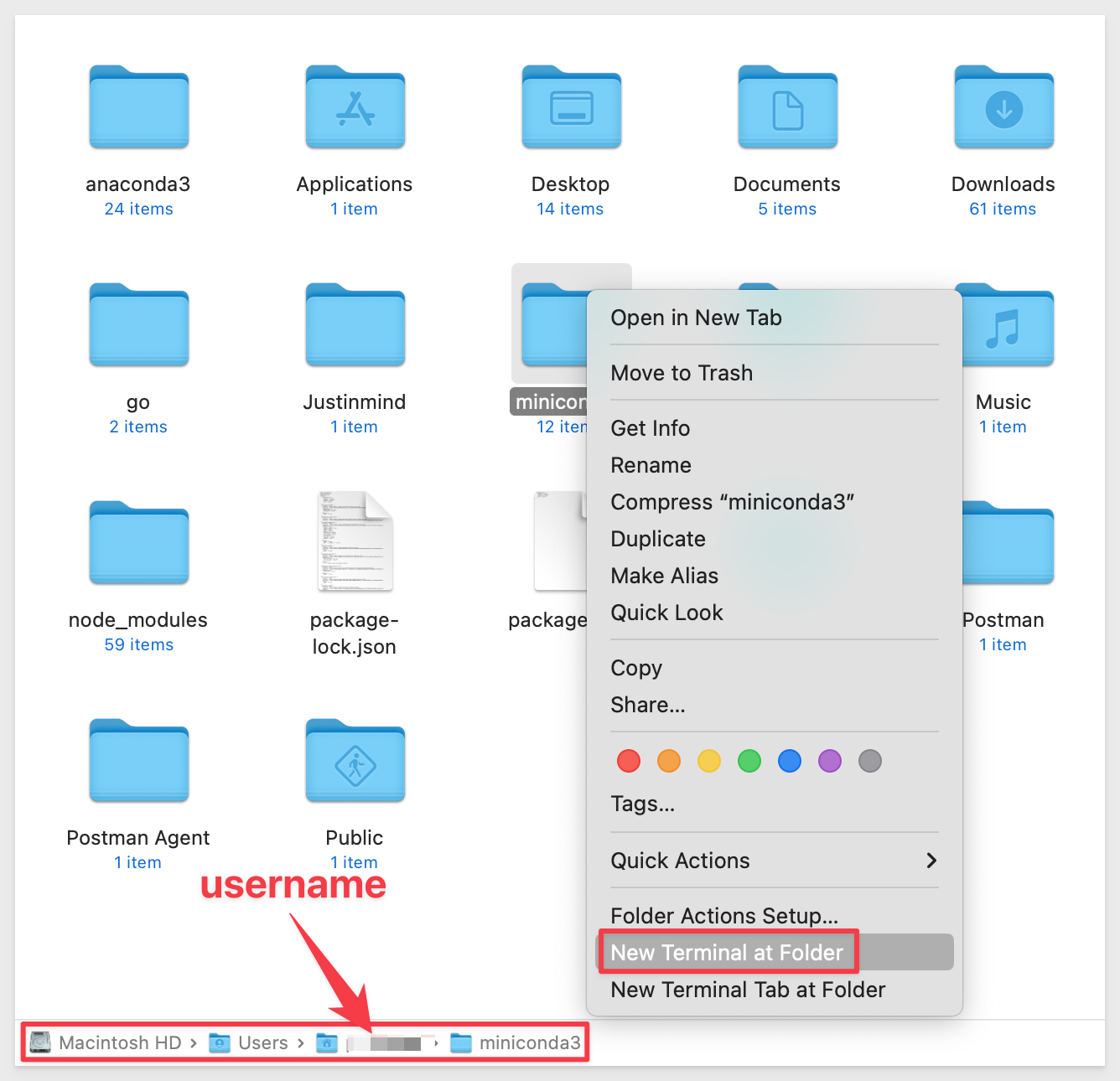
First, let's see what environments already exist. Run the command:
conda env list
We should see the "base" environment that is included with Miniconda.
Now let's create our "snowpark" environment for our VSCode project. Run the command:
conda create --name snowpark python=3.8
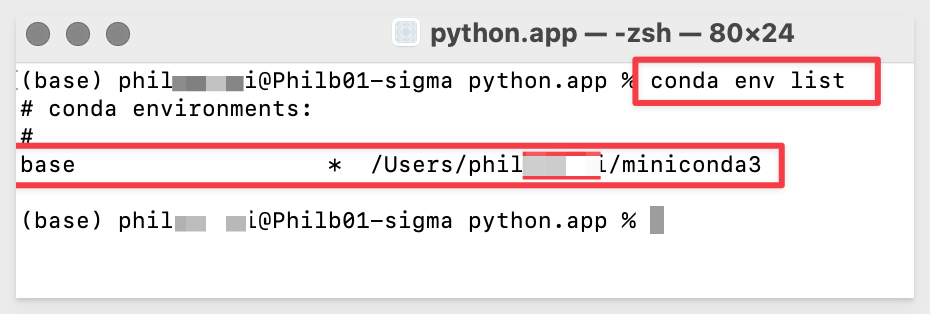
When prompted to proceed, type y and hit return:
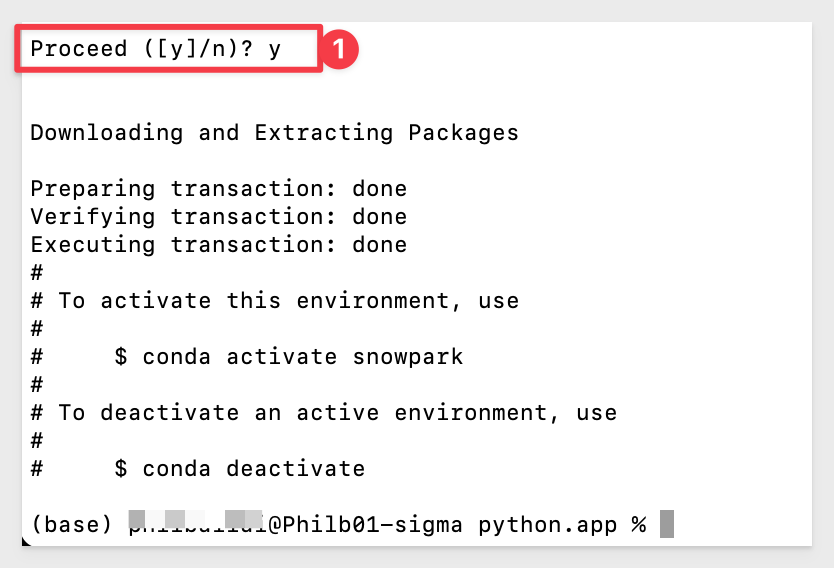
Listing the environments again, we should see base and snowpark with base being the current select noted by the "*":
conda env list
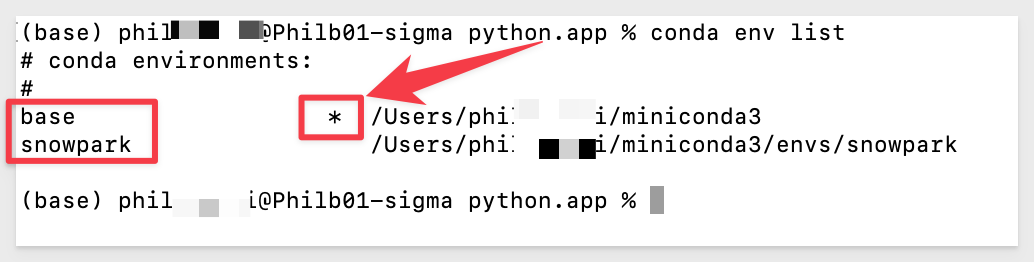
We are ready with our new Conda environment called snowpark.
Before we use this environment in VSCode, we should install packages we will plan to use later in this QuickStart, inside our snowpark environment.
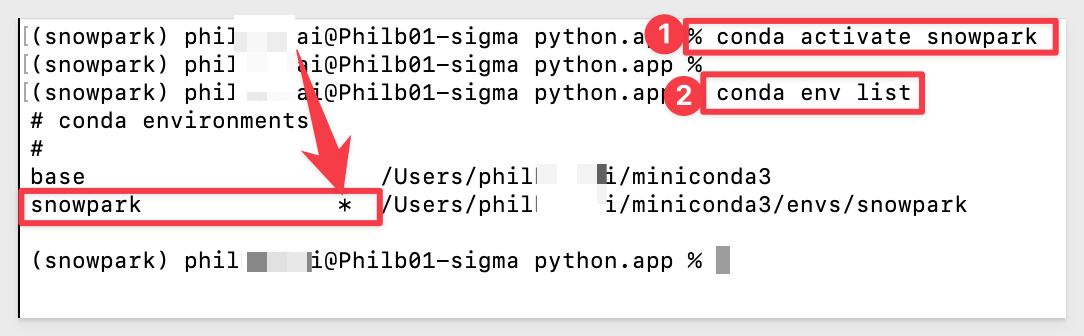
To install packages inside our snowpark environment, we need to first activate it. Run the command:
conda activate snowpark
snowpark is activated and we can confirm that by looking at the conda env list again:
The only package our UDF will require is called pandas, which includes several dependant packages.
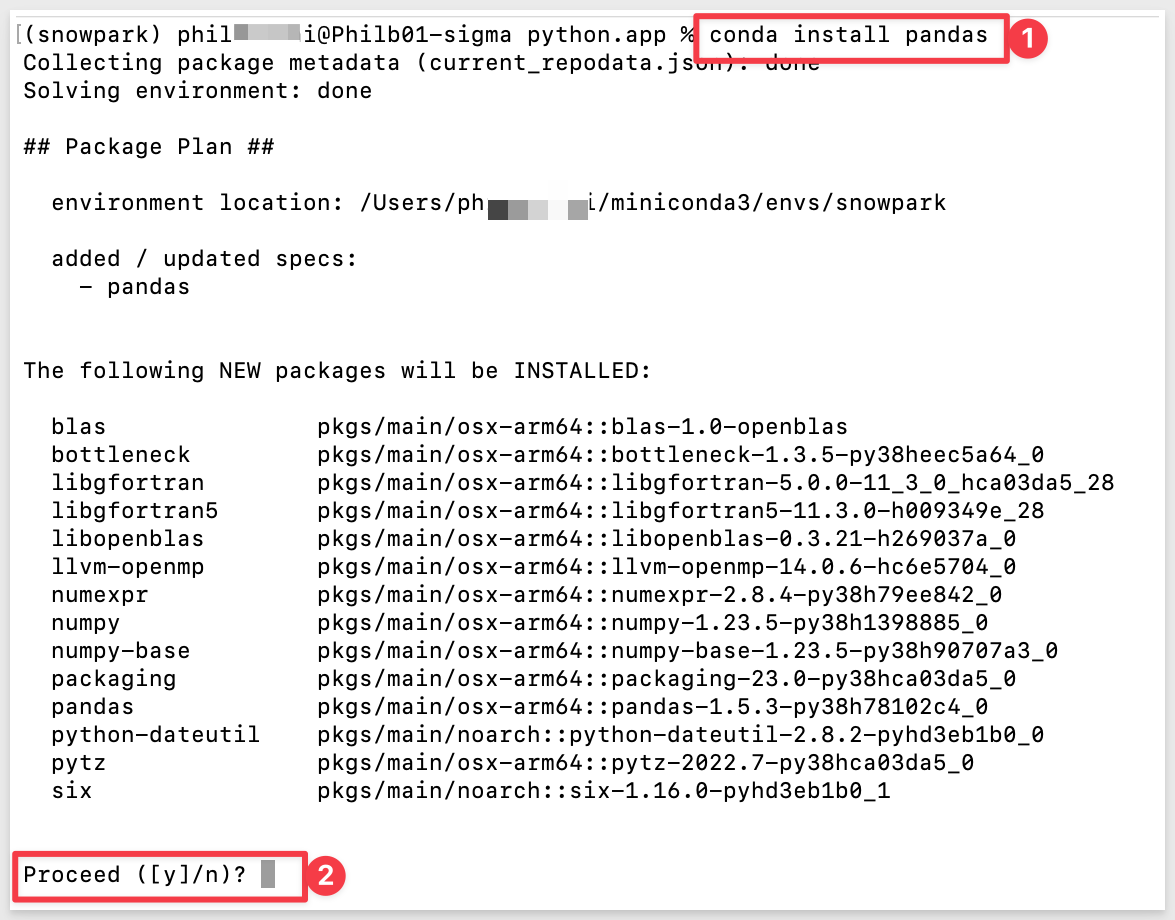
Run the command to install pandas in our snowpark environment:
conda install pandas
As before, when prompted to proceed, press y and hit enter:
The installation of pandas also installed many other dependencies. One is called NumPy. We will use this in our project, but won't need to install it again.
Snowpark Python Package
Snowflake provides a package that allows us to connect to Snowpark remotely.
Run the command to install it:
conda install snowflake-snowpark-python
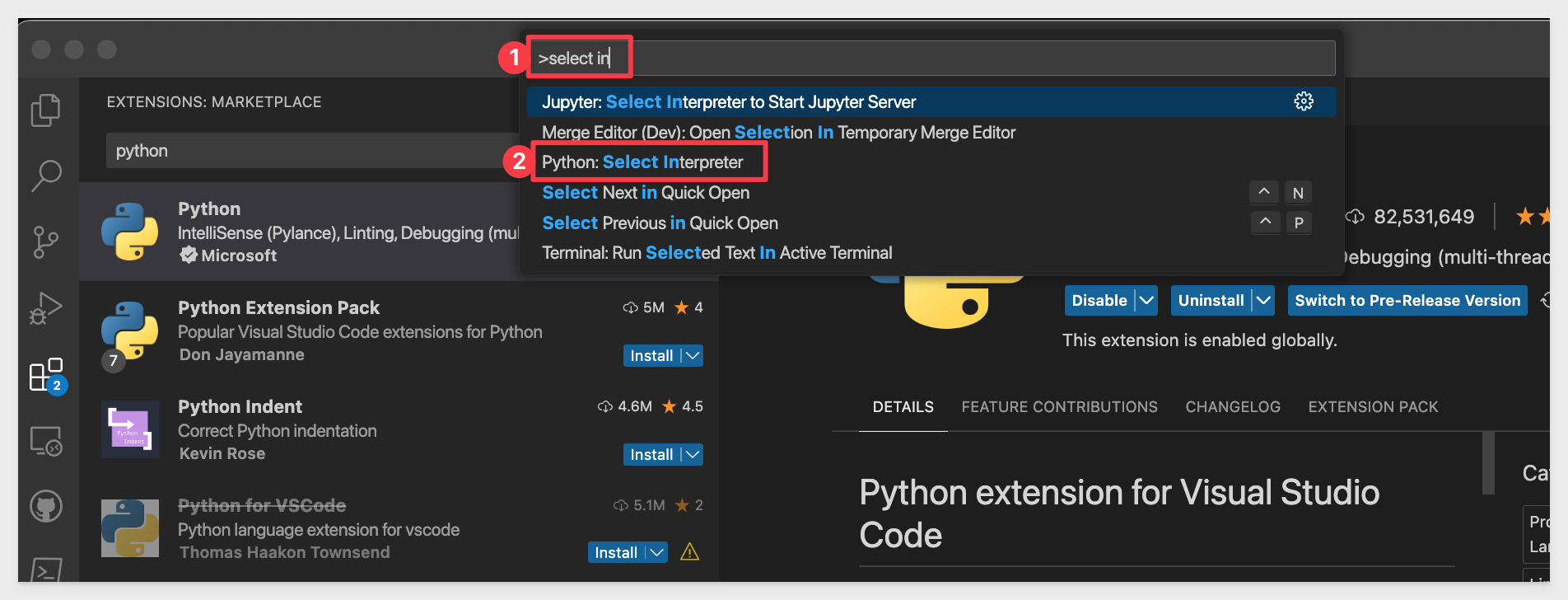
Open VSCode. We need to select the Python interpreter we want to use for our project.
Access the VSCode editor commands. Ctrl+Shift+P will bring you directly to the editor commands.
In the editor bar, type select inter and you should see Python: Select Interpreter listed. Select that.
There are a few (likely) versions installed and we want to select the one that is based on our snowpark environment.
We can tell which that is as it will say snowpark.
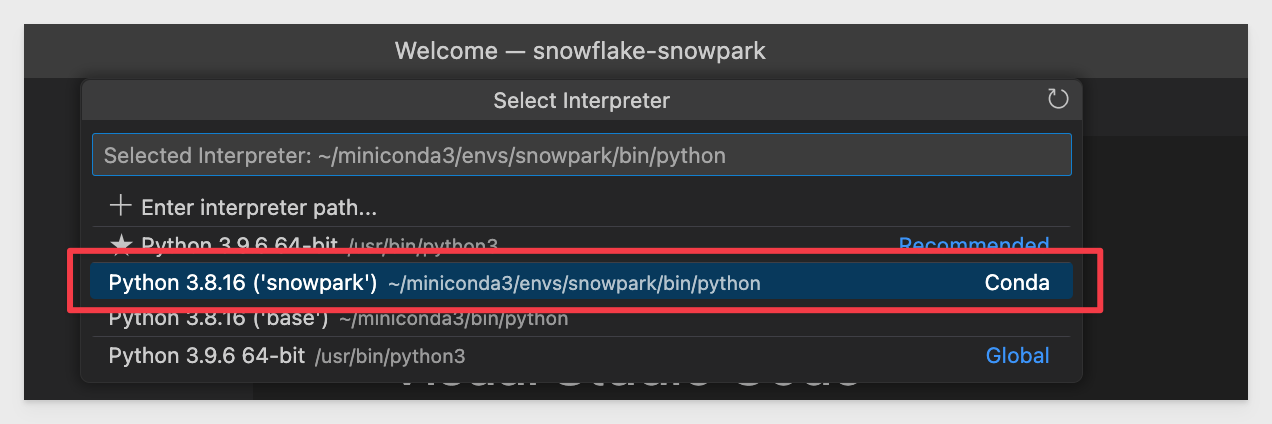
After restart (if required), VSCode will revert to the default Python environment so change that back to snowpark again.
Make sure that the Python Interpreter selected in blue is snowpark, indicating that it is active.
We are now setup to get connected to Snowflake from VSCode.
Part of the VSCode with Python includes Jupyter Notebooks.
A Jupyter notebook in VS Code is a file format that allows you to create and edit interactive documents that combine code, text, and visualizations. Jupyter notebooks are often used for data science, machine learning, and scientific computing tasks.
For the purposes of this QuickStart, they are not all that different than other tools you probably have used with a just a few built-in controls to locate while using the Notebook.
To create a new Jupyter notebook, just open the command palette in VSCode as before Ctrl + Shift + p and type "New Jupyter notebook" without any quotation, and click it to create a new notebook.
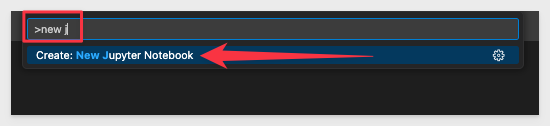
The first thing we prefer to do is save the blank workbook so that we can make incremental saves anytime we want.
Like any other application, click File > Save and give it name. We used getting-started.ipynb. In this case, the file extension (.ipynb) is important to use.
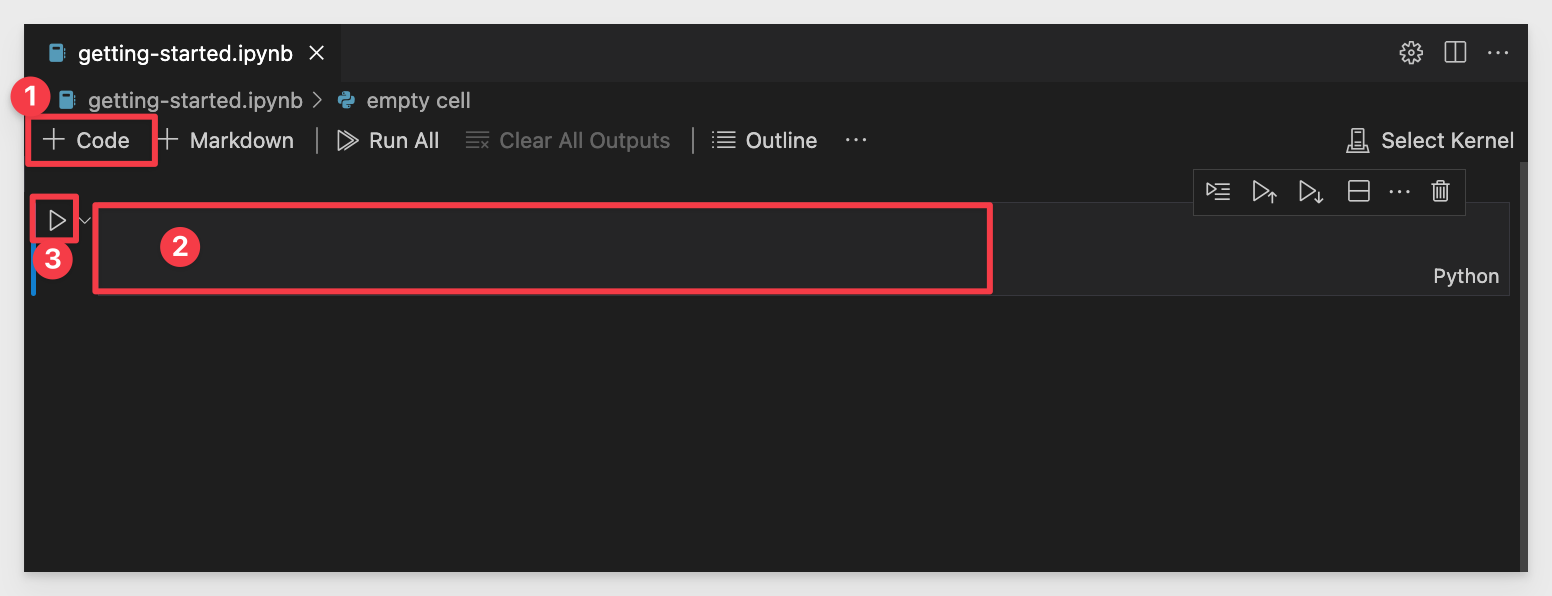
We have a blank Jupyter notebook. There are really three main features we will use in this exercise.
<li><strong>1:</strong> Adds a new Codeblock to the workbook. Codeblocks can be run independently, which is useful for our exercise.</li>
<li><strong>2:</strong> Working space of an individual codeblock.</li>
<li><strong>3:</strong> Runs the code in the codeblock that the arrow is adjacent to.</li>
With that out of the way, let's do a quick test to make sure all of this is working.
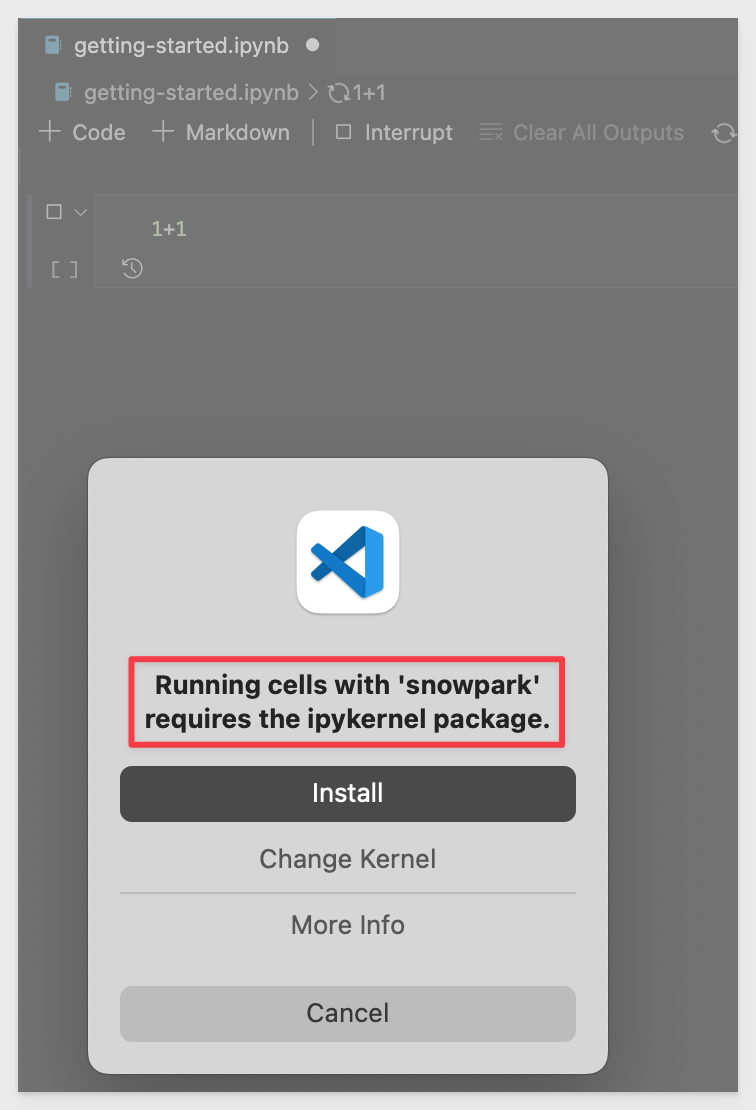
Type 1+1 in only codeblock and click the run (arrow) button on the left side of the codeblock.
If it produces an answer of 2, then it is working well.
In our case, an error is thrown and this is typically when using Miniconda, but simple to resolve. VSCode prompts to install the required packages so we can just select Install and let VSCode do the conda package install for us.
After the install is done (maybe 20 seconds), the re-run of our codeblock produces a positive result. Note the green checkmark; this is what we always want to see when testing.
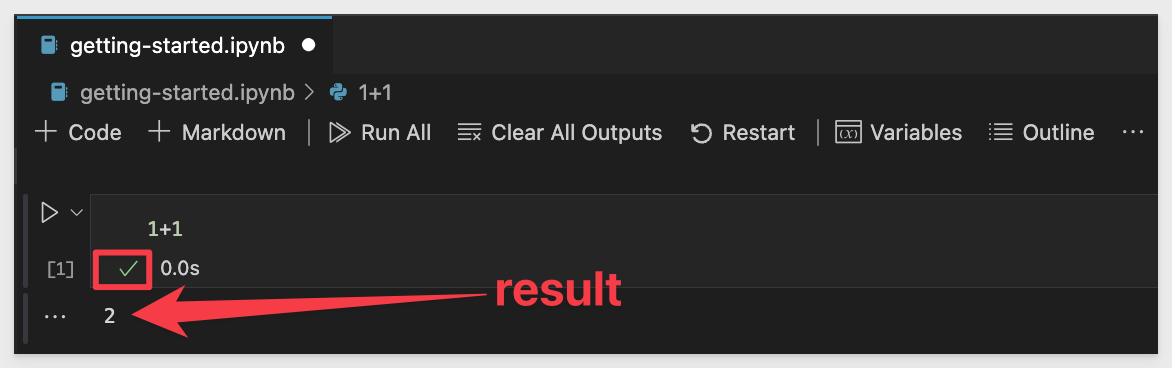
Now that we are sure that 1+1 = 2, we can move on.
Click the add a new codeblock (+Code).
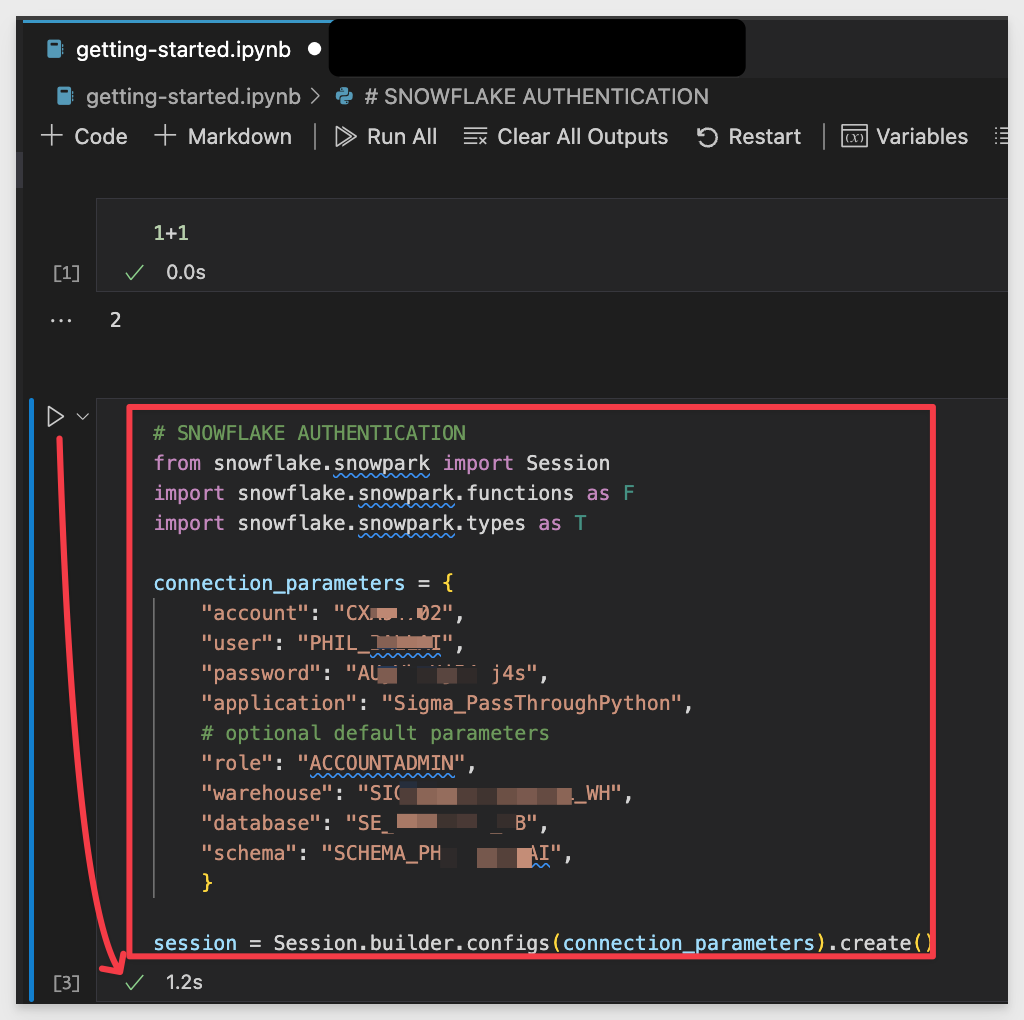
Copy this code into the new codeblock:
# SNOWFLAKE AUTHENTICATION
from snowflake.snowpark import Session
import snowflake.snowpark.functions as F
import snowflake.snowpark.types as T
connection_parameters = {
"account": "Your Snowflake Account Number",
"user": "Your Snowflake username",
"password": "Your Snowflake password",
"application": "Sigma_PassThroughPython",
# optional default parameters
"role": "ACCOUNTADMIN",
"warehouse": "Your warehouse",
"database": "your database",
"schema": "your schema",
}
session = Session.builder.configs(connection_parameters).create()
After you have configured the required values, run this codeblock as usual. We should get the positive result (green checkmark) indicating that we our VSCode project is connected to Snowflake, based on the configured parameters:
Before we move on, some words about Snowflake Role requirements for working with UDFs. We are using the Role ACCOUNTADMIN just to avoid some additional configuration steps but this is not best practice.
To publish a user-defined function (UDF) in Snowflake, you need (minimally) the "USAGE" privilege on the database and schema where the function is located, as well as the "CREATE FUNCTION" privilege.
The "USAGE" privilege allows you to execute the UDF, while the "CREATE FUNCTION" privilege enables you to create, alter, and drop functions.
Note that the user who creates the UDF automatically gets the "USAGE" and "CREATE FUNCTION" privileges on that function, but other users or roles need to be explicitly granted these privileges.
More information on granting privileges for UDFs is available here.
For our first UDF, we will create a simple (think "Hello World-like") UDF in Snowflake that can be later called with Sigma by name.
Our UDF will calculate the greatest common denominator (GCD) between two input values, using the NumpPy package.
A UDF that is shared and can be called by any Sigma user, using the Sigma user interface directly, is highly desirable.
Now that VSCode is connected to Snowflake, we want to create another Codeblock. This code defines our UDF which calculates the greatest common denominator (GCD) of two input numbers, in a Pandas DataFrame.
Define our greatest common denominator (GCD) UDF:
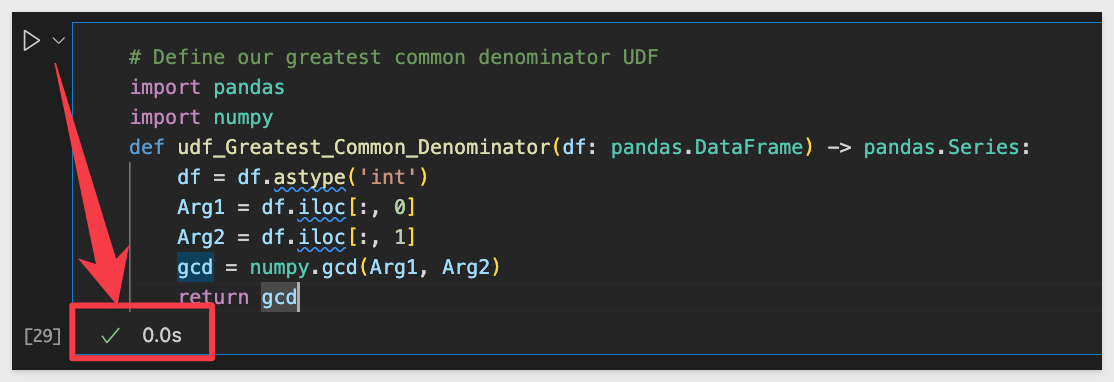
In a new codeblock, copy and paste this code, which defines our GCD UDF:
# Define our greatest common denominator UDF
import pandas
import numpy
def udf_Greatest_Common_Denominator(df: pandas.DataFrame) -> pandas.Series:
df = df.astype('int')
Arg1 = df.iloc[:, 0]
Arg2 = df.iloc[:, 1]
gcd = numpy.gcd(Arg1, Arg2)
return gcd
Here is a breakdown of what each line of the code does:
1: This is a comment that describes what the following code does.
# Define our greatest common denominator UDF

2: These two lines imports the panda and NumPy packages. NumPy provides a gcd function that we will use to calculate the GCD. Pandas will do the data manipulation in Snowflake. While we already have them installed in our local environment, they are not going to exist on our Snowpark instance for this UDF unless we specify to import it when the UDF is defined.
import pandas
import numpy
3: This line defines the UDF called udf_Greatest_Common_Denominator, which takes a single argument df of type pd.DataFrame, and returns a pd.Series object.
def udf_Greatest_Common_Denominator(df: pandas.DataFrame) -> pandas.Series:
4:This line converts the DataFrame df to an integer data type.
df = df.astype('int')
5: These two lines extract the first and second columns of the DataFrame df and assign them to Arg1 and Arg2, respectively.
Arg1 = df.iloc[:, 0]
Arg2 = df.iloc[:, 1]
6: This line uses the numpy.gcd function to calculate the GCD of Arg1 and Arg2, and assigns the result to the variable gcd.
gcd = numpy.gcd(Arg1, Arg2)
7: This line returns the GCD value as a pd.Series object from the UDF.
return gcd
Now that it is all explained, run the codeblock.
As before, we should see a green checkmark:
Register the GCD function in Snowflake
Our new UDF takes in two float arguments (the two columns in which to find the smallest common denominator against), so we need to specify that in the registrations using the input_types as:
[T.FloatType()]*2
This is used in the following codeblock.
Copy this code to a new codeblock in VSCode:
### Register UDF
udf_Greatest_Common_Denominator = session.udf.register(func=udf_Greatest_Common_Denominator,
name="GCD_UDF",
input_types=[T.FloatType()]*2,
return_type = T.FloatType(),
stage_location='@My_UDFS',
replace=True,
max_batch_size = 1000,
is_permanent=True,
packages=['NumPy','pandas'],
comment = "Algorithm to find Greatest Common Denominator",
session=session)
Some things to note:
1: We have to specify the NumPy and Pandas packages.
2: We decided to name it GCD_UDF. We will call this UDF by that name from Sigma later.
3: We have to make the registered UDF available to the Snowflake connection that is being used in Sigma. We will do that in a bit.
Run the codeblock. It will likely fail:
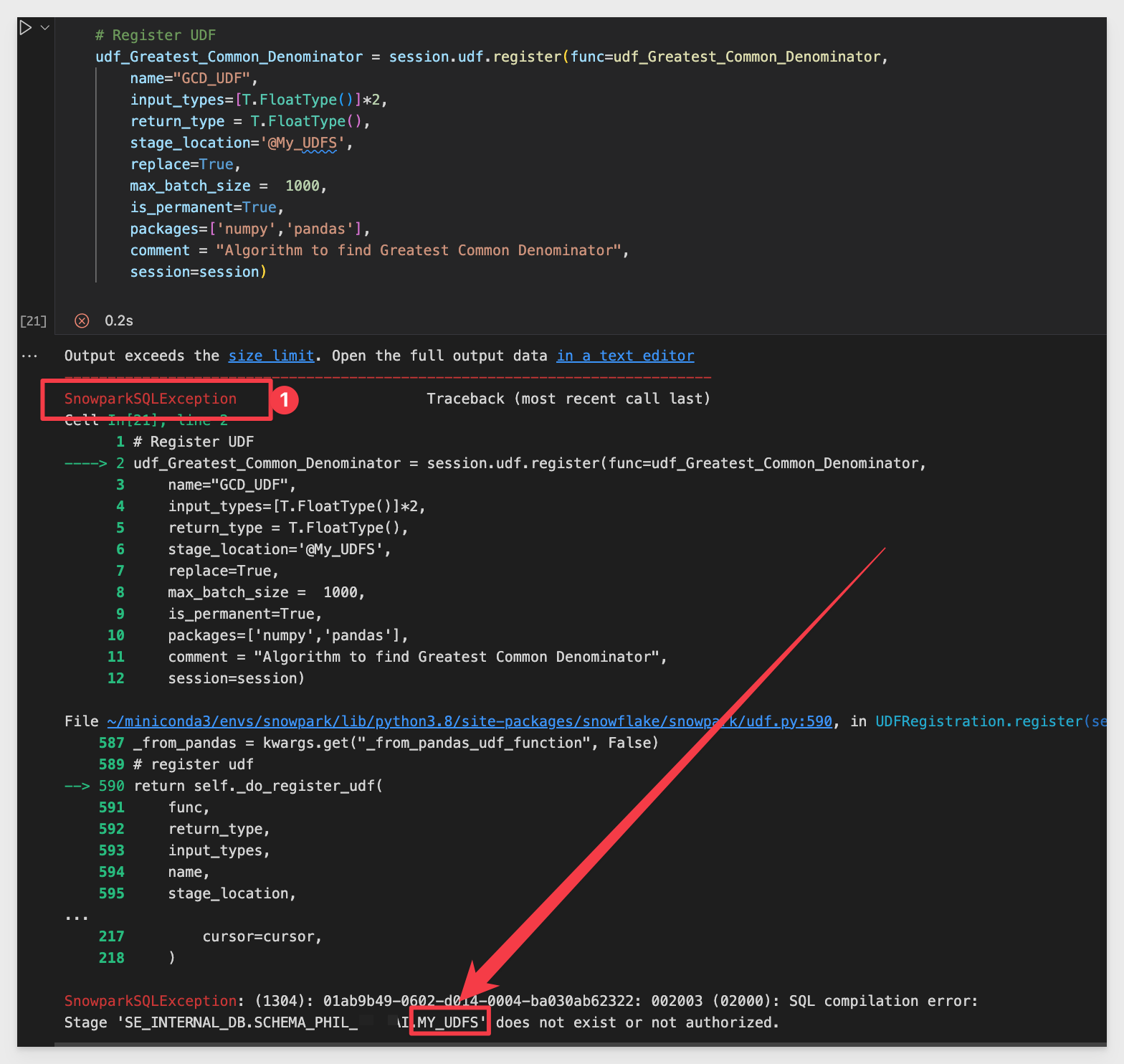
This is because we specified a Snowflake Stage, but forgot to create it. Lets do that.
In a Snowflake SQL Worksheet (not a Python one), run this command using the warehouse and database that we connected to Snowflake in VSCode. We need the Stage to exist where we want it to be.
CREATE STAGE IF NOT EXISTS My_UDFS

After creating the required Snowflake Stage, re-run takes a bit longer (we are loading package dependencies) to run:
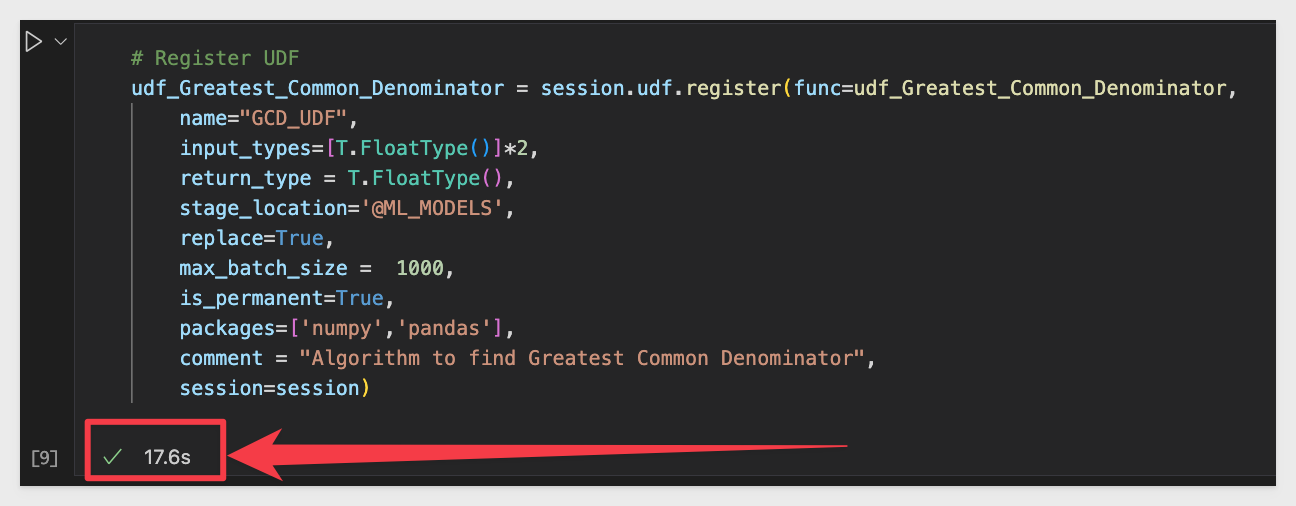
Lastly, we need to register the UDF (item #3 on the list) by running this code in a new VSCode codeblock:
query = session.sql('grant all on function GCD_UDF(float, float) to role ACCOUNTADMIN')
query.collect()

Login into Sigma and select Create New and then Workbook.
In the new Workbook, click + to add a new Table.
Select a source of WRITE SQL:
We need to select a connection for our custom SQL and need to use the Snowflake connection that we used in VSCode since that is where our UDF is published.
Once you have selected your connection, copy and paste the following SQL script in the codeblock.
This script will generate 100 rows with two columns of random numbers between 1 and 100 (and an Id column) that we will use as inputs to our GCD UDF.
SELECT
ROW_NUMBER() OVER (ORDER BY RANDOM()) AS id,
uniform(1, 100, random()) AS Min,
uniform(1, 100, random()) AS Max
FROM
TABLE(GENERATOR(ROWCOUNT => 100))
Run the command and observe the results:
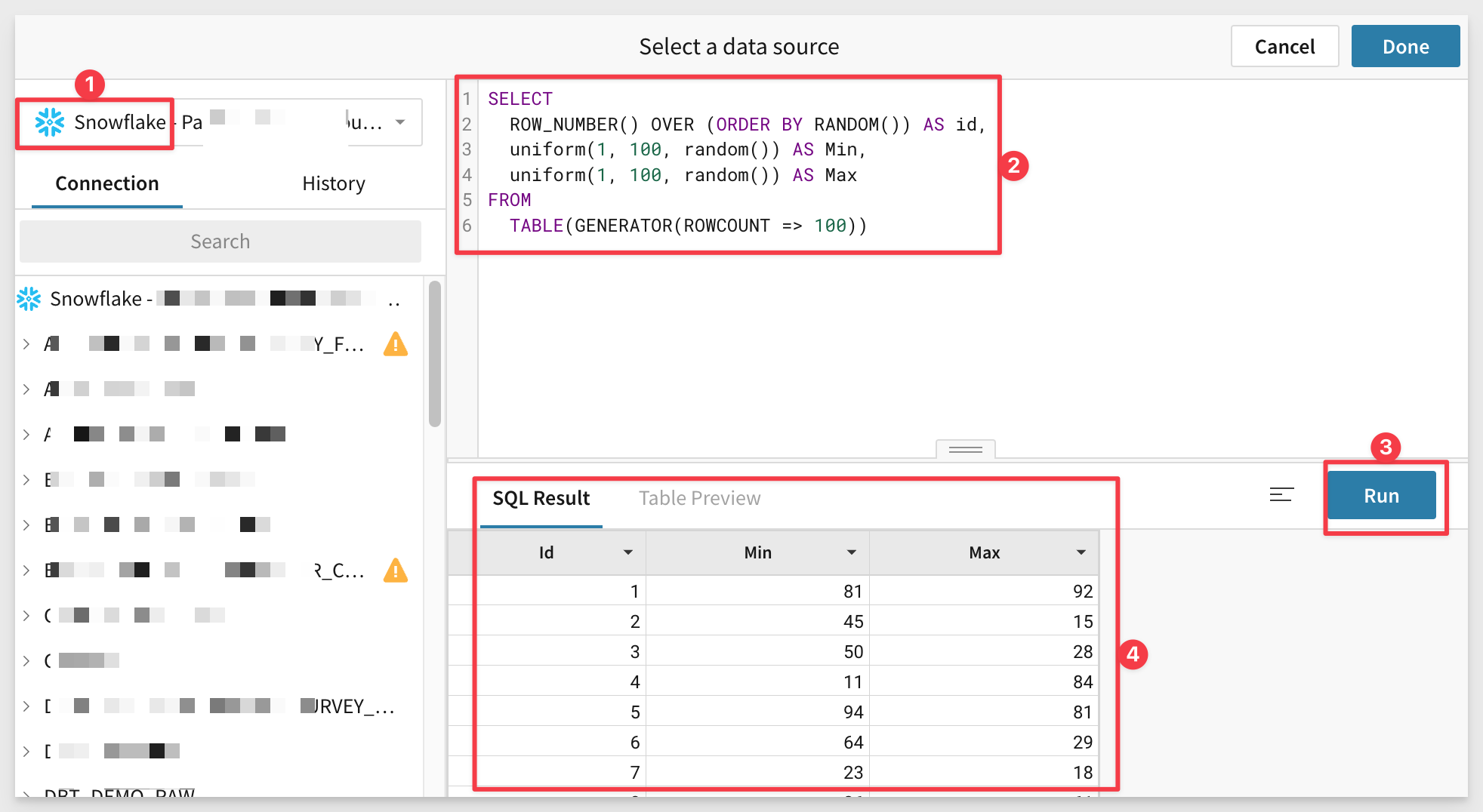
Now click Done.
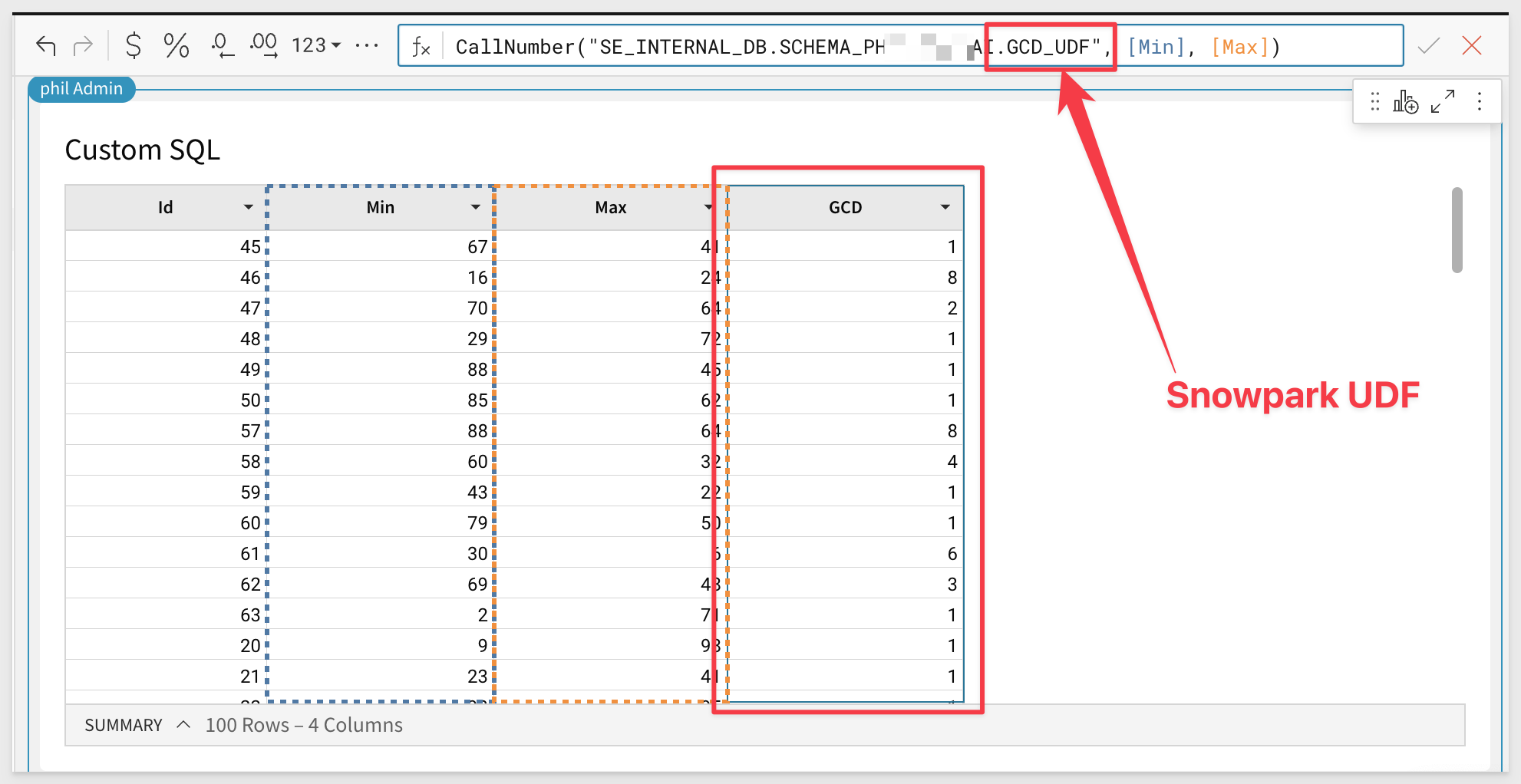
Back in the Workbook, click the Max column and select Add new column and rename it GCD:
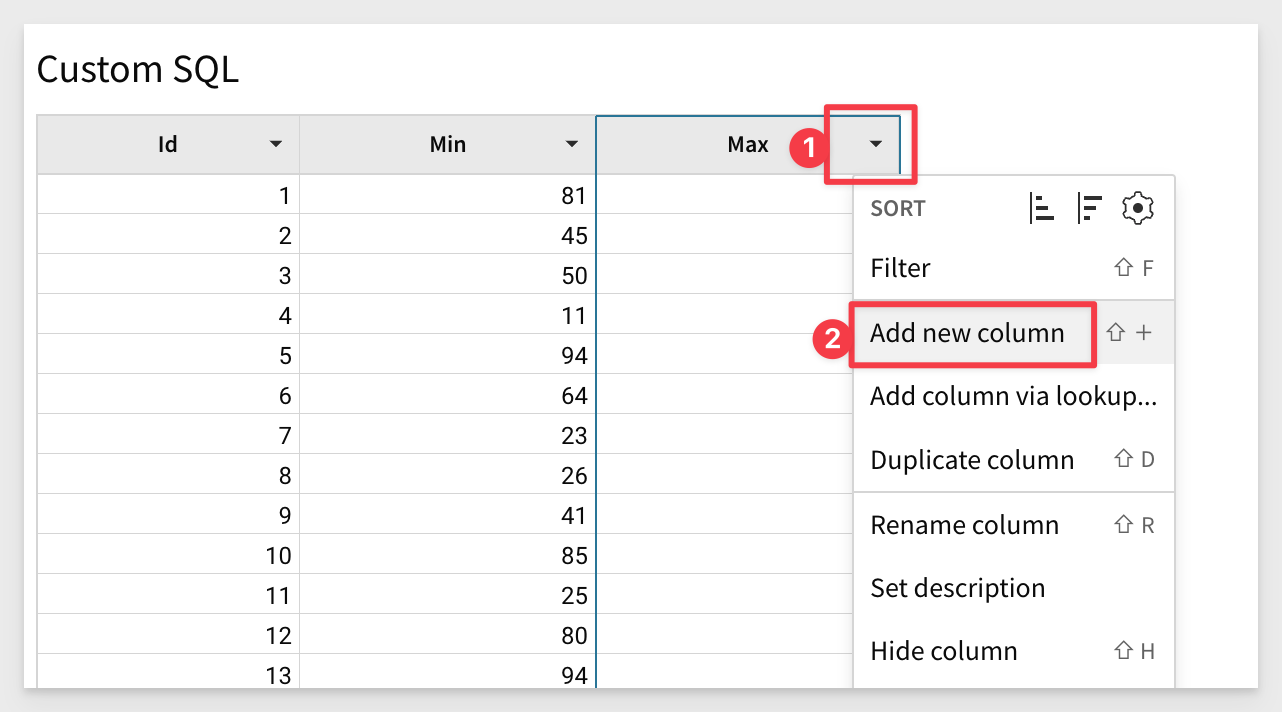
In the formula bar for the new column copy and paste this formula and click the checkmark to accept it:
CallNumber("SE_INTERNAL_DB.SCHEMA_PHIL_XXXXXX.GCD_UDF", [Min], [Max])
We now can see the UDF has calculated the greatest common denominator between the Min and Max columns in the GCD column.
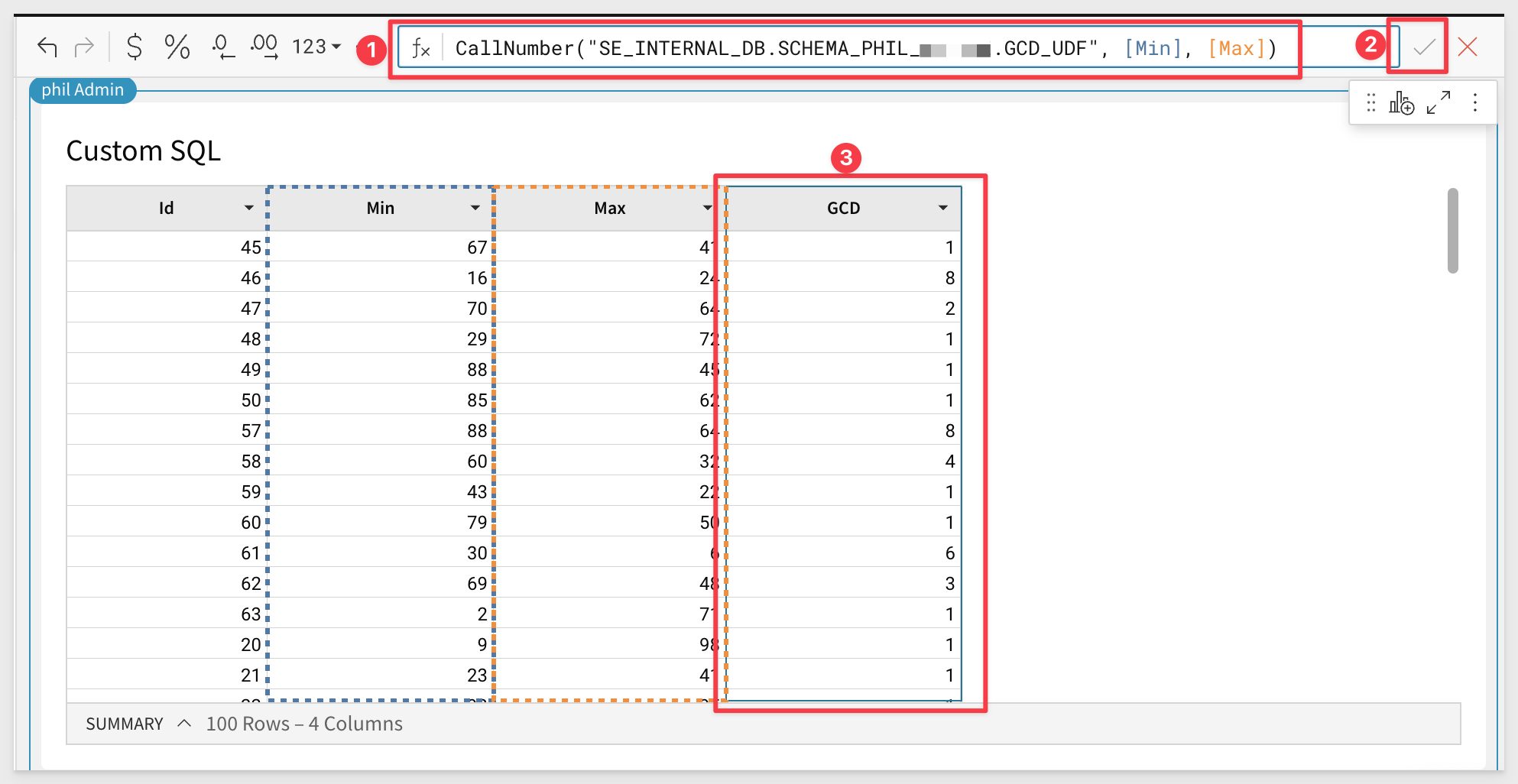
Congratulations; you have now created and used Snowflake Snowpark UDF in Sigma using Python.
In this QuickStart we created a local Python development environment and used it to create and publish a Snowflake Snowpark user defined functions (UDF). We then then learned how easy it is to call UDFs directly from Sigma.
Additional Resource Links
Be sure to check out all the latest developments at Sigma's First Friday Feature page!
Help Center Home
Sigma Community
Sigma Blog


